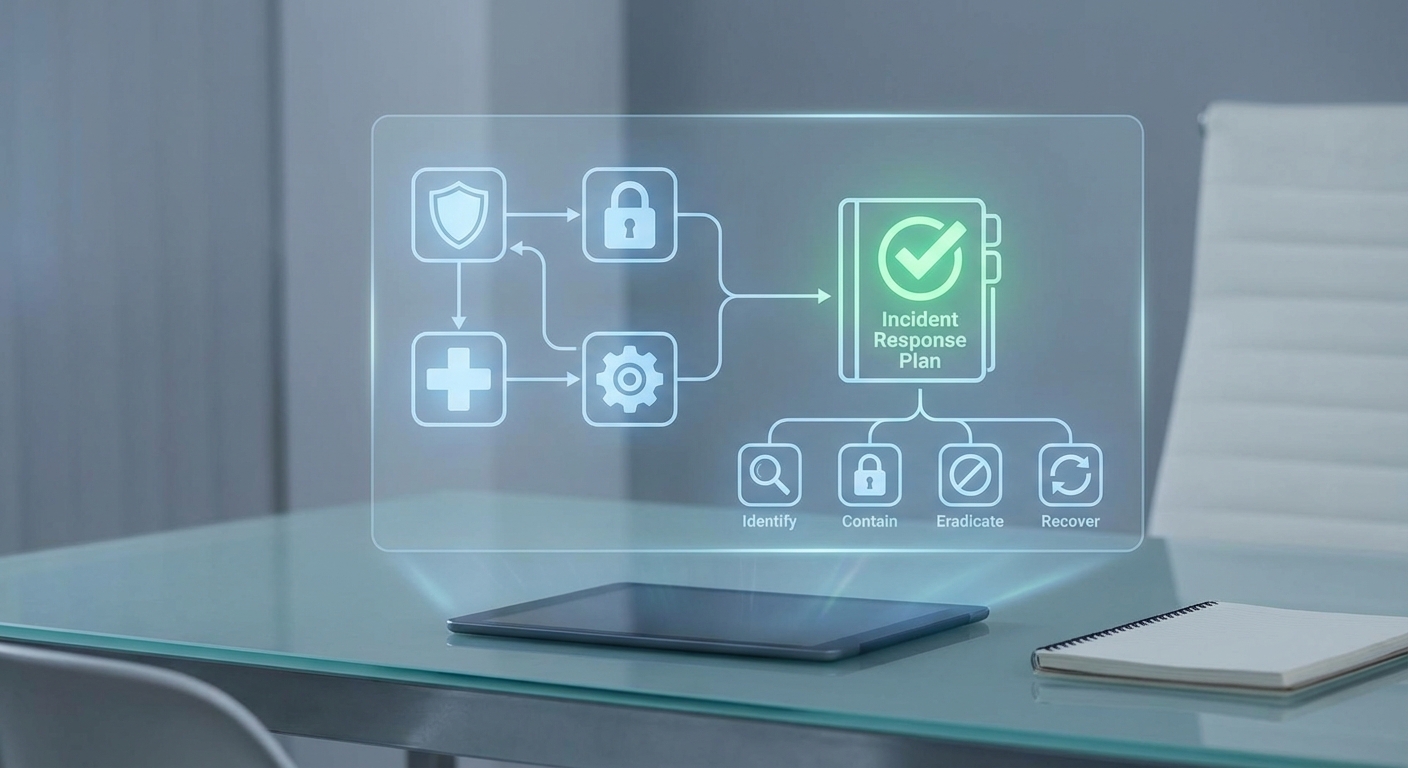
You’re staring at a ransomware notification on your screen at 3 AM. Your team is panicking. Nobody knows who to call first. Sound familiar? Most companies don’t fail because they lack security tools. They fail because they have no plan when things go sideways.
Building an incident response plan means defining six core phases: preparation, detection, analysis, containment, eradication, and recovery. Your plan must assign clear roles, establish communication protocols, document procedures step by step, and get tested regularly. A working plan turns chaos into coordinated action, cutting response time from hours to minutes and reducing damage by up to 70%.
Why Most Response Plans Collect Dust
Here’s the uncomfortable truth. Most organizations have an incident response plan sitting somewhere on a shared drive. It’s 47 pages long. Nobody has read it since it was written three years ago. When an actual incident happens, teams ignore it completely.
The problem isn’t the plan itself. It’s that most plans were built to satisfy compliance requirements, not to actually help people during a crisis.
A good plan is a tool your team reaches for instinctively. It should be clear enough that someone could follow it at 2 AM after being woken up. It needs to answer one question: what do I do right now?
The Six Phases That Form Your Foundation
Every effective incident response plan follows a framework. The most widely adopted comes from NIST, which breaks response into six phases. Think of these as your skeleton. Everything else hangs on this structure.
- Preparation: Build your team, gather tools, create playbooks
- Detection and Analysis: Spot the incident and figure out what’s happening
- Containment: Stop the bleeding without destroying evidence
- Eradication: Remove the threat completely
- Recovery: Restore systems and return to normal operations
- Post-Incident Activity: Learn from what happened and improve
Each phase needs specific actions, assigned people, and clear success criteria. You can’t skip steps or reorder them. They build on each other.
Building Your Response Team
You can’t respond to incidents alone. You need a team with clear roles and zero confusion about who does what.
Start with these core positions:
- Incident Commander: Makes final decisions, coordinates all activity
- Technical Lead: Handles the technical investigation and remediation
- Communications Lead: Manages internal and external messaging
- Documentation Lead: Records everything that happens
- Legal/Compliance Representative: Ensures regulatory requirements are met
Small teams often need people wearing multiple hats. That’s fine. Just make sure everyone knows which hat they’re wearing at any given moment.
Your team needs contact information for everyone. Not just email addresses. Phone numbers. Personal cell numbers. Backup contacts if someone is unreachable. Store this information somewhere accessible even if your email system is down.
Creating Playbooks That Actually Help
Generic response procedures don’t work under pressure. You need specific playbooks for specific scenarios.
Pick your top five threats. For most organizations, that’s:
- Ransomware
- Data breach
- Phishing compromise
- Denial of service
- Insider threat
For each threat, write a playbook that walks through detection, initial response, containment, and recovery. Use simple language. Number every step.
Here’s what a ransomware playbook opening looks like:
“If you see a ransom note or files with unusual extensions: (1) Immediately disconnect the affected device from the network by unplugging the ethernet cable or disabling WiFi. (2) Do not turn off the device. (3) Call the Incident Commander at [number]. (4) Take a photo of the ransom note with your phone.”
Notice the specificity. No jargon. Clear physical actions. This is what people can actually follow during a crisis.
Detection Mechanisms You Can’t Skip
You can’t respond to what you don’t see. Detection is where most small organizations struggle.
Your detection layer needs:
- Security Information and Event Management (SIEM): Collects and analyzes log data
- Endpoint Detection and Response (EDR): Monitors individual devices for suspicious behavior
- Network Monitoring: Watches for unusual traffic patterns
- User Reporting: Makes it easy for employees to report suspicious activity
The last one matters more than you think. Your users see things your tools miss. Create a simple reporting mechanism. A dedicated email address. A Slack channel. A phone number. Make reporting feel safe, not like admitting failure.
Documentation Standards That Save You Later
When an incident happens, you’ll want to remember what you did and when you did it. Six months later, when regulators ask questions, you’ll need proof.
Create a standard incident log template. Every entry needs:
- Timestamp (use UTC to avoid timezone confusion)
- Action taken
- Person who took the action
- Result or outcome
- Any relevant screenshots or evidence
Assign one person as your dedicated scribe. Their only job during an incident is documentation. This person doesn’t fix things. They write down what everyone else is doing.
Store your logs somewhere immutable. You need to prove they weren’t altered after the fact.
Communication Protocols That Prevent Panic
Bad communication during an incident creates secondary disasters. Rumors spread. Customers panic. Employees post on social media.
Your plan needs three communication tracks:
Internal Communication: How does the response team talk to each other? Use a dedicated channel. Not your regular Slack. Not email. A separate war room that only exists during incidents.
Internal Stakeholder Updates: How do you keep executives and other departments informed? Set a regular update cadence. Every 2 hours during active incidents. Use a standard template so people know what to expect.
External Communication: Who talks to customers, partners, and the public? Only one person should be authorized to make external statements. Everyone else directs questions to that person.
Create message templates ahead of time. You can customize them during an incident, but having a starting point prevents you from saying something you’ll regret.
Testing Your Plan Without Breaking Things
A plan that’s never been tested is just creative writing. You need to practice.
Start with tabletop exercises. Gather your team in a room. Present a scenario. Walk through your response step by step. No computers. Just conversation.
Example scenario: “It’s Friday at 4 PM. Your EDR tool alerts that three computers in accounting are exhibiting ransomware behavior. What do you do?”
Let people answer. Find the gaps. Update your plan.
After a few tabletop exercises, run a simulation. Pick a time. Simulate an actual incident. Follow your playbooks. See what breaks.
Test at least twice a year. After major changes to your infrastructure. After team changes. After updating your plan.
Common Mistakes That Undermine Everything
| Mistake | Why It Hurts | How to Fix It |
|---|---|---|
| Plans that are too long | Nobody reads them during a crisis | Keep core procedures under 10 pages |
| Assuming tools will work | Systems fail during incidents | Have offline backup procedures |
| No practice | Theory doesn’t survive contact with reality | Test every six months minimum |
| Unclear authority | People argue about decisions during incidents | Name one incident commander |
| Ignoring legal early | Regulatory violations compound the damage | Include legal from the start |
The biggest mistake is perfectionism. You’ll never have a perfect plan. Ship version one. Use it. Improve it. A mediocre plan you actually follow beats a perfect plan that sits unused.
Tools and Resources Worth Having Ready
Your response team needs a ready kit. Think of it like a fire extinguisher. You hope you never use it, but when you need it, you need it immediately.
Essential items:
- Offline documentation: Printed copies of your core playbooks
- Forensic tools: Pre-configured USB drives with investigation software
- Contact lists: Phone numbers for vendors, legal counsel, insurance, law enforcement
- Communication devices: Phones or tablets that aren’t connected to your corporate network
- Evidence collection: External drives for preserving data
- Credential vault: Emergency access credentials stored securely offline
Store physical items in a known location. Multiple locations if you have multiple offices. Make sure night shift and weekend staff know where to find them.
Integrating with Business Continuity
Your incident response plan doesn’t exist in isolation. It connects to your broader business continuity strategy.
Some incidents require business continuity activation. A ransomware attack that takes down critical systems isn’t just a security incident. It’s a business continuity event.
Define clear triggers. At what point does an incident escalate to business continuity? Who makes that decision? How do the teams coordinate?
Your incident commander and business continuity coordinator need to be in constant contact during major events. They’re managing different aspects of the same crisis.
Legal and Regulatory Considerations
Different industries have different notification requirements. Healthcare has HIPAA. Finance has various regulations. Europe has GDPR. Many US states have breach notification laws.
Your plan must include:
- Breach notification timelines: How many hours or days do you have to notify?
- Required information: What must you include in notifications?
- Notification methods: How should you contact affected parties?
- Regulatory contacts: Who do you need to inform beyond affected individuals?
Work with legal counsel to build this section. Don’t guess. The penalties for getting this wrong can exceed the cost of the original incident.
Measuring Your Response Effectiveness
How do you know if your plan is working? You need metrics.
Track these key indicators:
- Mean Time to Detect (MTTD): How long between incident start and detection?
- Mean Time to Respond (MTTR): How long between detection and initial response?
- Mean Time to Contain (MTTC): How long to stop the incident from spreading?
- Mean Time to Recover (MTTR): How long to restore normal operations?
After each incident, calculate these metrics. Look for trends. Are your times improving? Where are the bottlenecks?
Also track qualitative factors. Did people follow the plan? Was the documentation helpful? What would they change?
Continuous Improvement Through Post-Incident Reviews
Every incident is a learning opportunity. The post-incident review is where learning happens.
Schedule this review within one week of closing an incident. While memories are fresh. Longer than that and people forget details.
Use a blameless approach. You’re not looking for who screwed up. You’re looking for what in your systems, processes, or plan made it possible for things to go wrong.
Ask these questions:
- What happened? (Timeline of events)
- What went well? (Things to keep doing)
- What went poorly? (Things to change)
- What surprised us? (Gaps in our assumptions)
- What are we changing? (Specific action items)
Document everything. Track action items. Assign owners. Set deadlines. Review progress in your next team meeting.
Update your plan based on what you learned. Your plan should evolve after every incident.
Keeping Your Plan Current
Your environment changes constantly. New systems. New threats. New team members. Your plan needs to keep pace.
Set a review schedule:
- Full review annually: Read the entire plan, update everything that’s changed
- Quarterly updates: Review contact lists, tool access, key procedures
- After major changes: New infrastructure, significant team changes, major incidents
Assign someone to own plan maintenance. This can’t be everyone’s job or it becomes nobody’s job.
Version your plan. Track what changed and when. This helps during audits and proves you’re maintaining it actively.
Your Plan Starts Now
The best time to create your incident response plan was before your last incident. The second best time is right now.
Start small. Pick one scenario. Write one playbook. Test it once. Build from there. A simple plan you actually use will protect you better than a comprehensive plan that never leaves the shelf. Your future self, standing in front of a crisis at 3 AM, will thank you for the clarity you’re building today.